Efficiently Fine-tuning Large Language Models with QLoRA: An Introductory Guide
Fine-tuning large language models (LLMs) such as LLaMA and T5 can produce impressive results, but the memory and hardware required for traditional 16-bit fine-tuning can be a major obstacle. A new method called QLoRA (Quantized Low-Rank Adapter) changes that, enabling efficient fine-tuning on large models using much less memory. This article simplifies the core concepts behind QLoRA, how it utilizes quantization, and how it allows for high-performance model customization on a single GPU.
What is QLoRA?
QLoRA is a method that allows fine-tuning of quantized models using Low-Rank Adapters (LoRA), making it possible to achieve high performance with a fraction of the typical memory usage. By freezing the original 4-bit quantized model and backpropagating gradients only through lightweight LoRA adapters, QLoRA reduces the memory needed to fine-tune a large model, like one with 65 billion parameters, from over 780GB to under 48GB. This makes it possible to fine-tune large models on a single GPU.
How Does QLoRA Work?
QLoRA introduces three major innovations that enable efficient tuning of quantized models without sacrificing performance.
- 4-Bit NormalFloat (NF4): This data type optimizes how quantized model weights are stored, reducing memory consumption while maintaining accuracy. Unlike other 4-bit types, NF4 preserves model performance by effectively representing the model’s weight distribution.
- Double Quantization (DQ): Double Quantization reduces memory even further by quantizing the scaling factors of the initial quantization step, which adds memory efficiency without losing accuracy.
- Paged Optimizers: These manage memory spikes that may occur during gradient updates, prevent memory overflows, and optimize memory usage by moving unused memory to CPU memory when necessary.
How Quantization and LoRA Work in QLoRA?
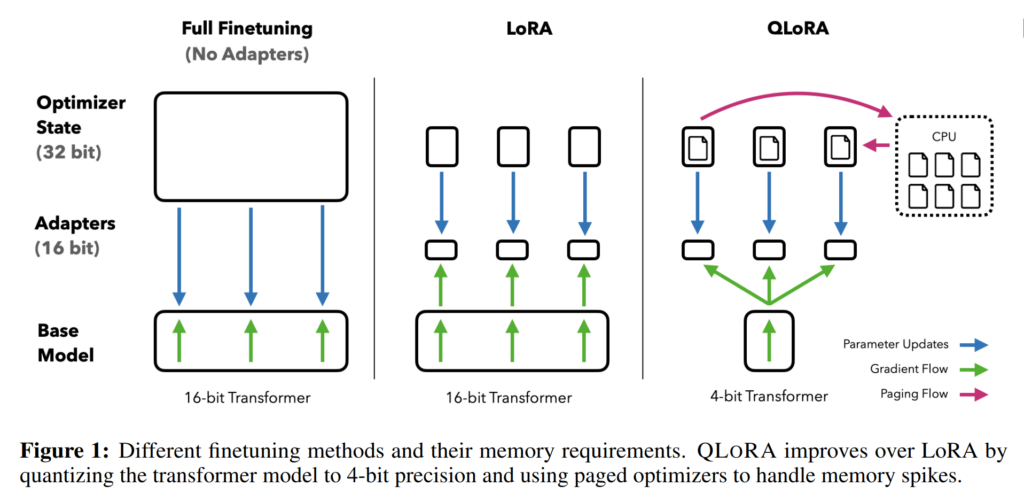
Quantization simplifies the model’s weights to a lower bit representation, reducing the memory needed to store and compute these values. QLoRA quantization process can be divided into three major steps; Block-Wise Quantization, Double Quantization for Constants, and LoRA Adapters.
- Block-Wise Quantization: QLoRA divides the model’s parameters into small chunks and quantizes them individually. This prevents outliers (unusually high or low values) from affecting the quantization accuracy.
- Double Quantization for Constants: Quantization introduces scaling constants to keep values within a manageable range. In QLoRA, these constants are further quantized to reduce memory usage without sacrificing performance.
- LoRA Adapters: Instead of updating all model weights, QLoRA uses a low-rank adapter, which is a small trainable matrix that makes adjustments to the original model. With this approach, only LoRA parameters are updated during training, while the main model weights remain unchanged, reducing memory requirements.
Why is QLoRA Better?
With QLoRA, fine-tuning models can be achieved at a much lower memory cost, allowing for more flexible and accessible model adjustments. Here’s how it performs across key areas.
- Memory Efficiency: Using NF4 and Double Quantization, QLoRA achieves state-of-the-art performance with significantly lower memory requirements, making it possible to run large models on a single, affordable GPU.
- Adaptability: Because QLoRA’s LoRA adapters are applied across all layers of the model, it maintains high performance similar to traditional 16-bit fine-tuning without needing the same hardware resources.
- Speed: Memory paging ensures that QLoRA models can process larger batches without slowing down training, as page swapping between CPU and GPU is handled automatically when memory spikes occur.
Results and Performance
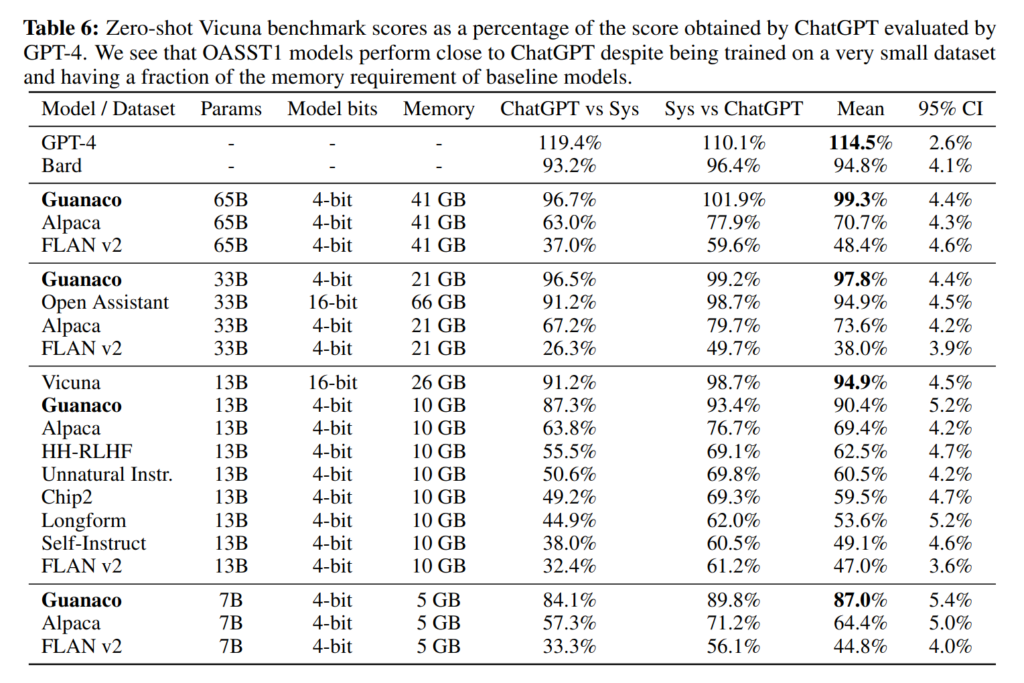
QLoRA achieves nearly identical performance in tests to a fully fine-tuned 16-bit model, even on challenging benchmarks. The QLoRA fine-tuned Guanaco model performs at 99.3% of ChatGPT’s accuracy on the Vicuna benchmark after just 24 hours of training on a single GPU.
Why QLoRA Matters?
QLoRA’s ability to optimize large models without high-end hardware democratizes access to advanced AI tools, putting state-of-the-art language models at the disposal of small teams and individual researchers. Additionally, QLoRA is highly memory efficient, paving the way for fine-tuning on-device models for applications such as privacy-preserving AI.
Conclusion
QLoRA offers a new, accessible way to optimize large language models without the prohibitive storage costs required by traditional methods. Combining 4-bit quantization with efficient adapter fine-tuning, QLoRA makes powerful tuning available to a wide range of users. For those looking to adapt large language models to their specific needs, QLoRA is a breakthrough technology worth considering.
For more details, you can check the following resources:
Leave a Reply
Want to join the discussion?Feel free to contribute!