Understanding Walk Forward Validation in Time Series Analysis: A Practical Guide
Time series analysis is crucial in various fields, from predicting stock market trends to forecasting weather patterns. However, simply building a time series model isn’t enough; we need to ensure that the model is accurate and reliable. This is where validation comes in. Validation is evaluating how well a model performs on unseen data, ensuring it can generalize beyond the data it was trained on. For time series models, validation is especially important because the data is often dependent on time, and traditional validation techniques like train-test splits may not be suitable due to the sequential nature of the data. In this blog post, we’ll explore Walk Forward Validation, one of the powerful techniques for evaluating time series models.
Why Do We Need Validation in Time Series Models?
Imagine you’re building a model to predict tomorrow’s temperature. You can’t just randomly split your data into training and testing sets like regular data. Why? Because time series data has a natural order, and that order matters! Today’s temperature is influenced by yesterday’s temperature, not next week’s temperature.
So we need validation that can help us in the following ways:
- Ensure our model works well on unseen data
- Avoid overfitting (when a model learns the noise in the training data)
- Simulate real-world conditions where we make predictions using only past data.
Why Walk Forward Validation?
To answer this query, we need to explore some of the most common and widely used validation techniques. Understanding these methods will help us grasp the scenarios in which each technique is suitable and why and when Walk Forward Validation might be the best choice. Below, we have listed these popular validation methods along with relevant details.
1. K-fold Cross-Validation Method
Splits the data into k equal parts (folds). The model is trained on k-1 folds and tested on the remaining fold, rotating until each fold has been used as the test set once.
Advantages:
- Uses all data for both training and testing
- Provides more robust performance estimates
- Good for small datasets
Disadvantages:
- Breaks temporal order
- Can lead to data leakage
- Future data might be used to predict past
- Doesn’t respect time series nature
Usage:
- Non-time series problems
- Time series without strong temporal dependencies
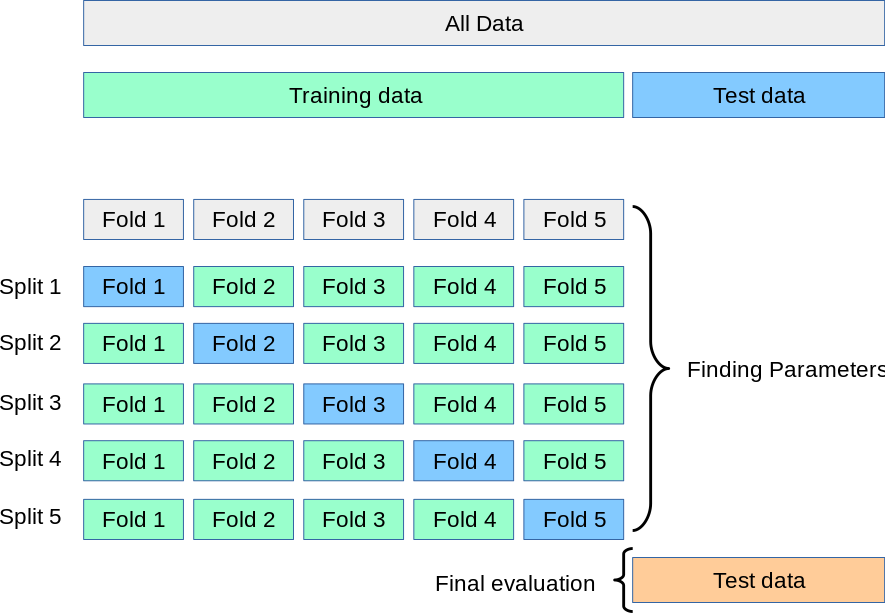
Source: scikit-learn 1.5.2 documentation
2. Leave-One-Out Cross-Validation (LOOCV)
This is a special case of k-fold where k equals the number of observations. Each observation is used as the test set while the remaining data is used for training, repeating for every observation.
Advantages:
- Maximizes training data
- Good for very small datasets
- Provides unbiased error estimation
Disadvantages:
- Computationally expensive
- High variance in error estimation
- Breaks temporal dependencies
- Not suitable for time series
Usage:
- Very small datasets
- When computational cost isn’t a concern

Source: Dataaspirant
3. Bootstrapping Validation
Involves randomly sampling data with replacement to create multiple training sets. This approach helps estimate the accuracy and variance of the model by training on different subsets of the original data.
Advantages:
- Works well with small datasets
- Provides confidence intervals
- Robust performance estimation
Disadvantages:
- Breaks temporal order
- Can include future data in training
- Not suitable for time series
- Computationally intensive
Usage:
- Small non-time series datasets
- When uncertainty estimation is important
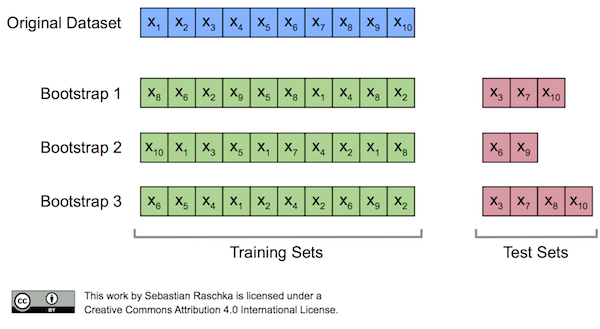
Source: mlxtend
4. Nested Cross-Validation
This method uses two loops of cross-validation: the outer loop estimates the model’s performance, while the inner loop selects the best model parameters, ensuring unbiased evaluation and effective hyperparameter tuning.
Advantages:
- Unbiased performance estimation
- Good for hyperparameter tuning
- Robust model selection
Disadvantages:
- Breaks temporal order
- Can include future data in training
- Not suitable for time series
- Computationally intensive
Usage:
- Small non-time series datasets
- When uncertainty estimation is important
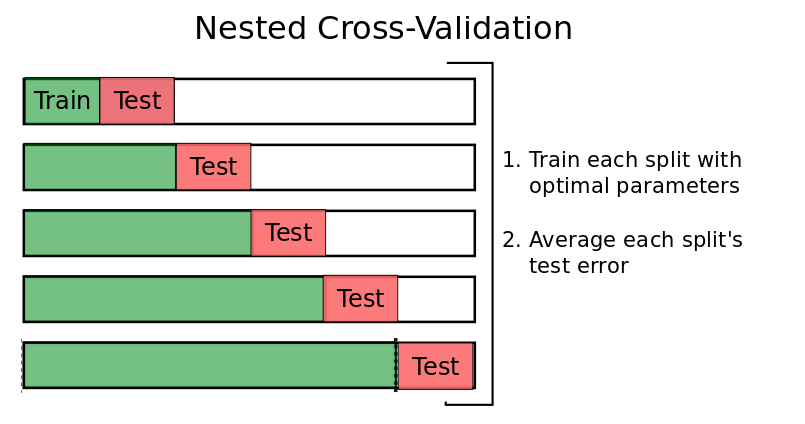
Source: Medium
5. Hold-Out Validation Method
This approach splits the data into training and testing sets based on a specific time point, typically using a 70-30 or 80-20 ratio. It is straightforward and quick, suitable for time-independent datasets but may not work well for time series data.
Advantages:
- Simple to implement and understand
- Fast computation
- Good for very large datasets
Disadvantages:
- Wastes a significant portion of data for testing
- High variance in model performance estimation
- Doesn’t account for temporal dependencies
- Single train-test split might not be representative
Usage:
- Initial quick model evaluation
- Very large time series where computational efficiency is crucial
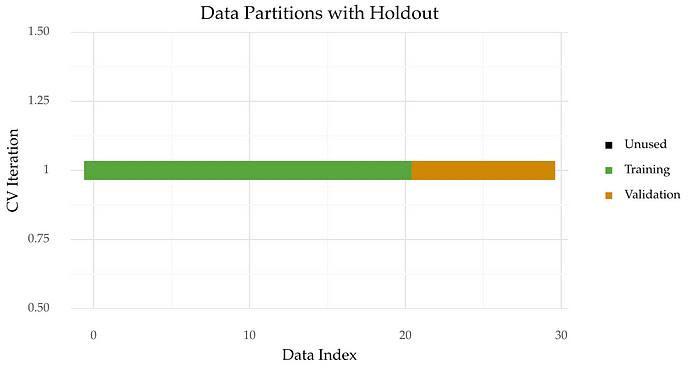
Source: Medium
6. Time Series Cross-Validation
Uses an expanding window approach, creating multiple train-test splits while maintaining the time order. This method ensures that future data is never used to predict past values, making it ideal for time-dependent datasets.
D
Advantages:
- Maintains temporal order
- Uses multiple evaluation periods
- More robust than single-split
Disadvantages:
- Early predictions based on less data
- Computationally more expensive
- Fixed window size might not capture all patterns
Usage:
- Time series with moderate temporal dependency
- When computational resources allow
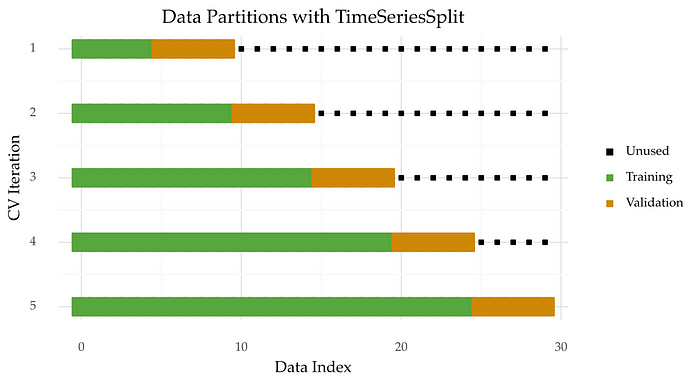
Source: Medium
7. Walk-Forward Validation
Utilizes a rolling window approach where the model is trained and tested on consecutive periods. This technique allows the model to be updated continuously, closely simulating real-world forecasting scenarios.
Advantages:
- Maintains temporal order
- Simulates real-world forecasting
- Captures evolving patterns
- Detects concept drift
- Consistent training window size
Disadvantages:
- Computationally intensive
- Requires careful window size selection
- May need multiple configurations
Usage:
- Financial time series
- Weather forecasting
- Any time series with evolving patterns
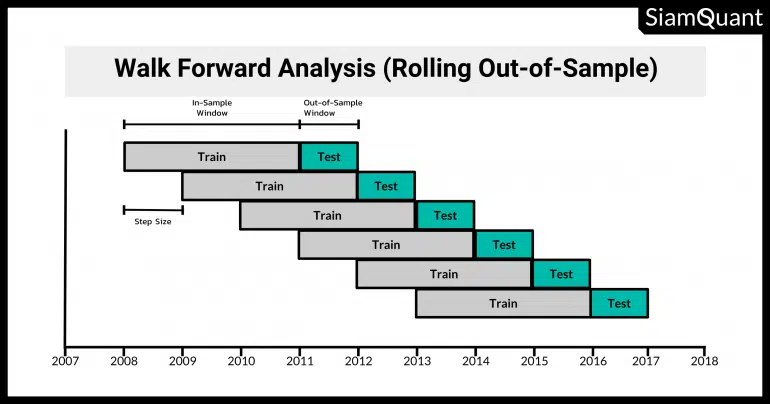
Source: Walk Forward Analysis – SiamQuant
We can observe how different validation technique is used to evaluate model performance on unknown data. To understand how walk forward is better for Time Series we can look at the following summary table:
| Method | Temporal Order | Computational Cost | Data Efficiency | Suitable for Time Series | Risk of Data Leakage |
| K-fold | ❌ | Medium | High | ❌ | High |
| LOOCV | ❌ | Very High | Very High | ❌ | High |
| Bootstrap | ❌ | High | High | ❌ | High |
| Nest Cross Validation | ❌ | Very High | High | ❌ | High |
| Hold-Out | ✅ | Low | Low | Partially | Low |
| Cross-Validation | ✅ | High | Medium | ✅ | Low |
| Walk-Forward Validation | ✅ | Medium | Medium | ✅ | Low |
Steps for Performing Walk-Forward Validation
- Initialize Parameters
- Set training window size a.k.a. In-Sample Window (e.g., 12 months)
- Set testing window size a.k.a. Out-of-Sample Window (e.g., 1 month)
- Set step size (e.g., 1 month)
- First Iteration
- Training: Months 1-12
- Testing: Month 13
- Record predictions and errors
- Second Iteration
- Training: Months 2-13
- Testing: Month 14
- Record predictions and errors
- Continue Process
- Keep “rolling” forward until the end of the dataset
- Each step moves both windows forward
- Calculate Performance
- Aggregate errors across all iterations
- Analyze performance trends over time
Practical Example: Temperature Forecasting
Let’s implement Walk Forward Validation using a simple temperature forecasting example in Python.
Import libraries
Generate Sample Daily Temperature Data
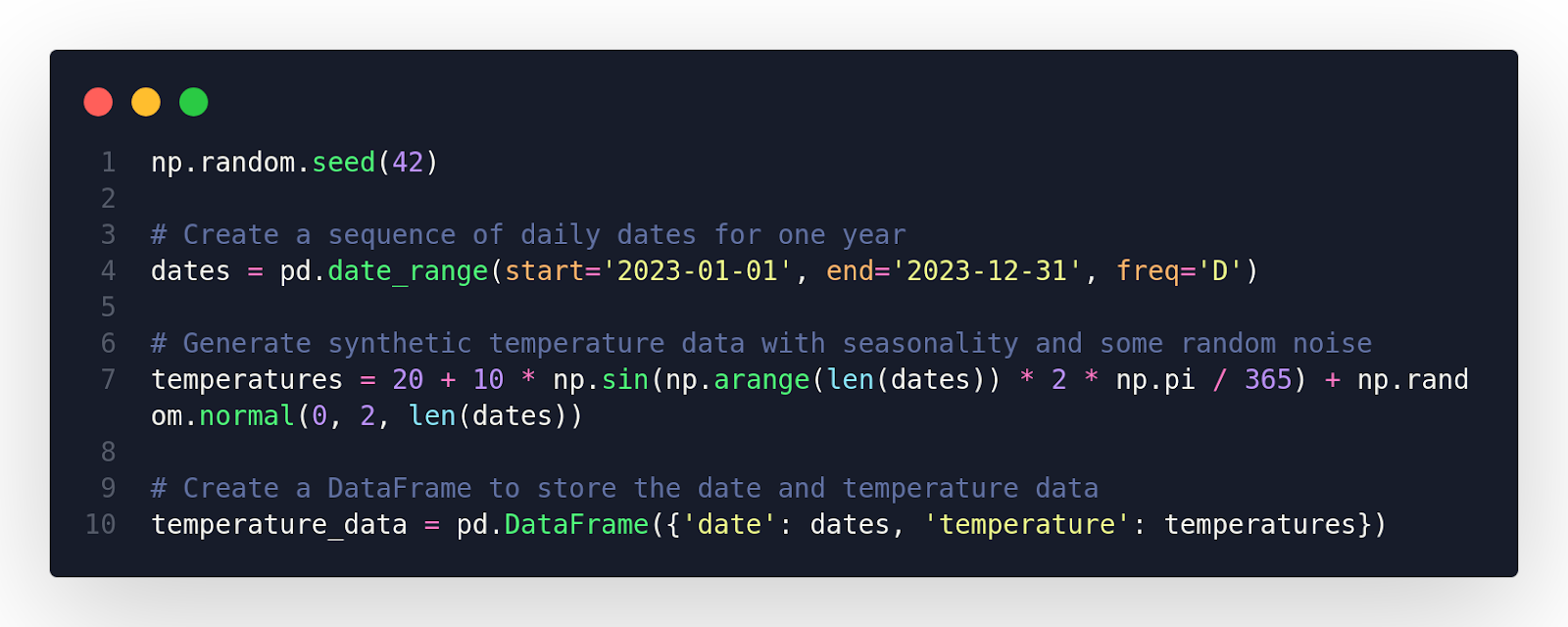
Sample Temperature Data
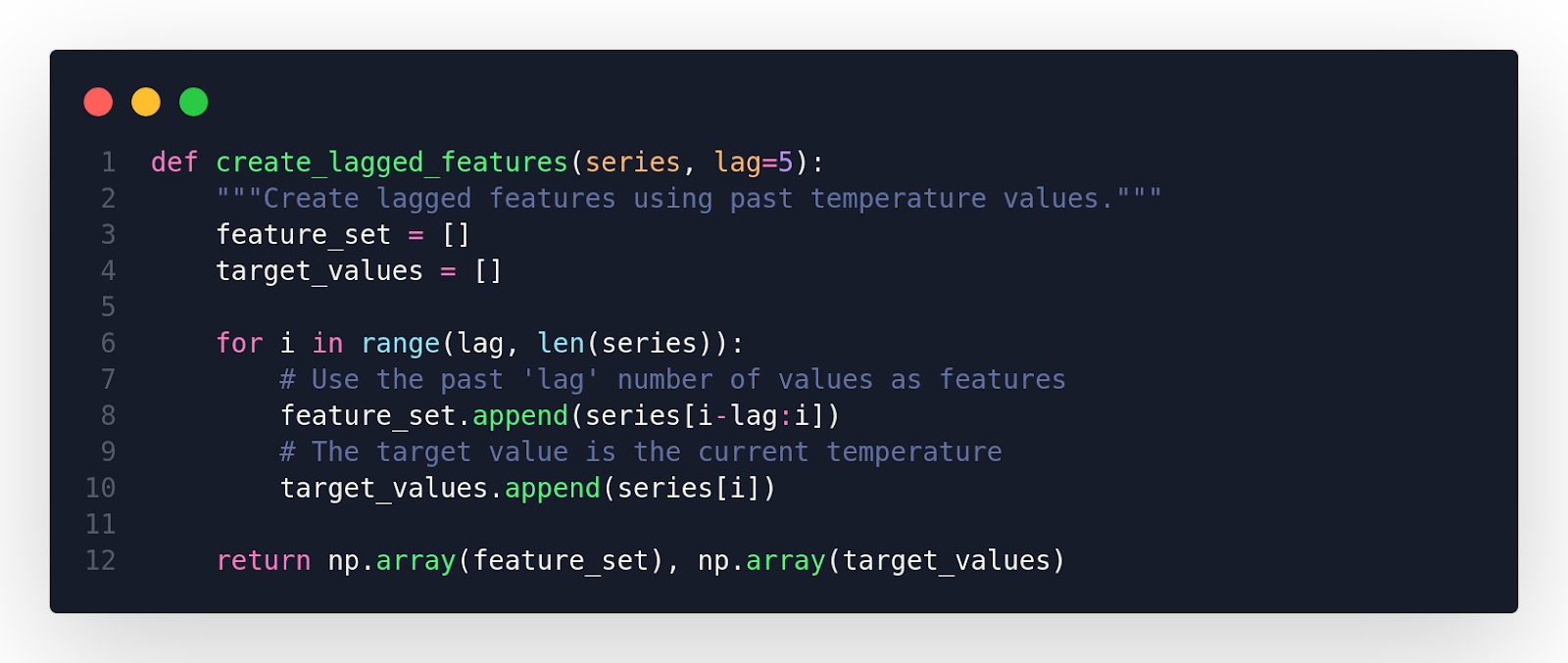
Function to Generate Temperature Features
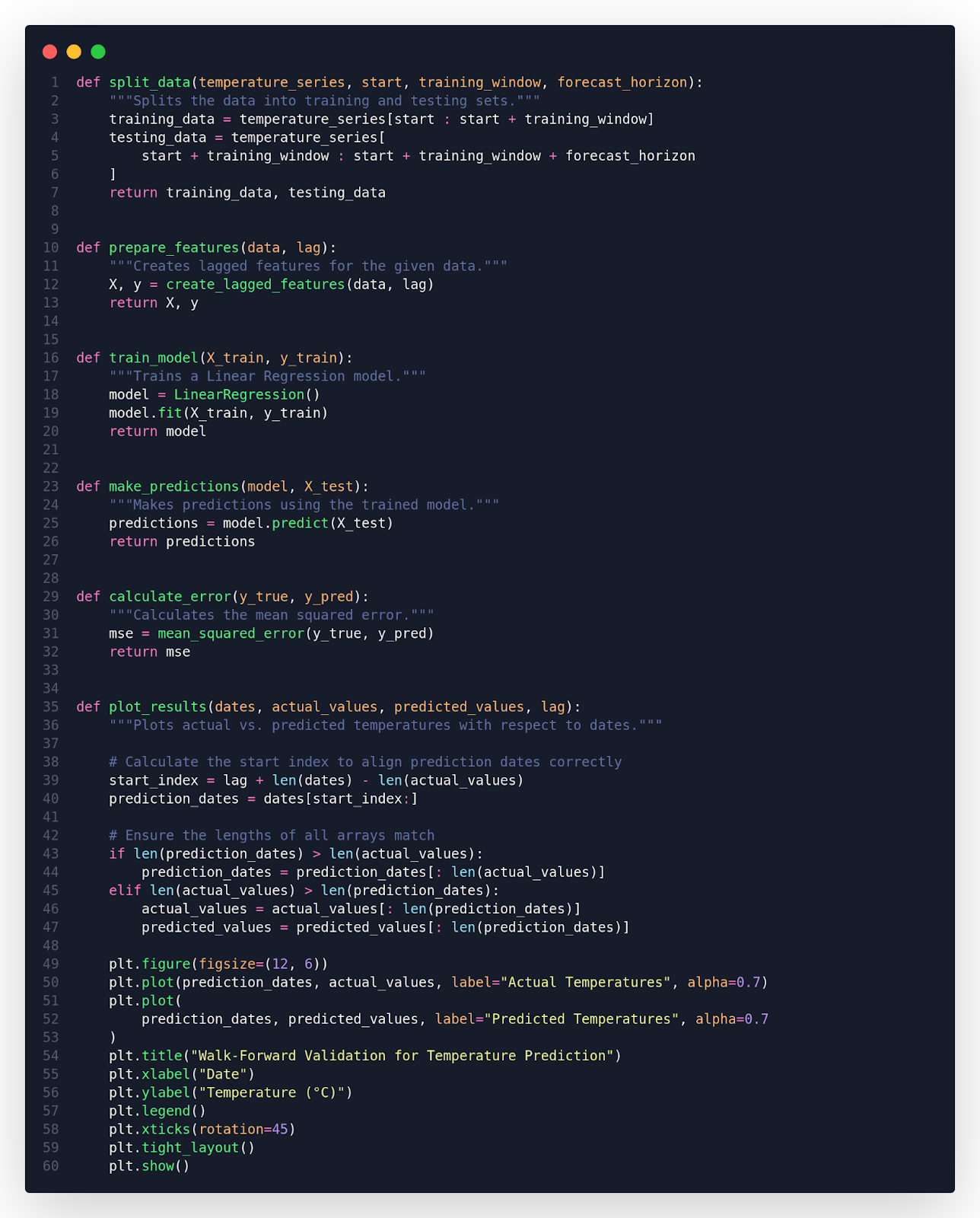
Helper Functions
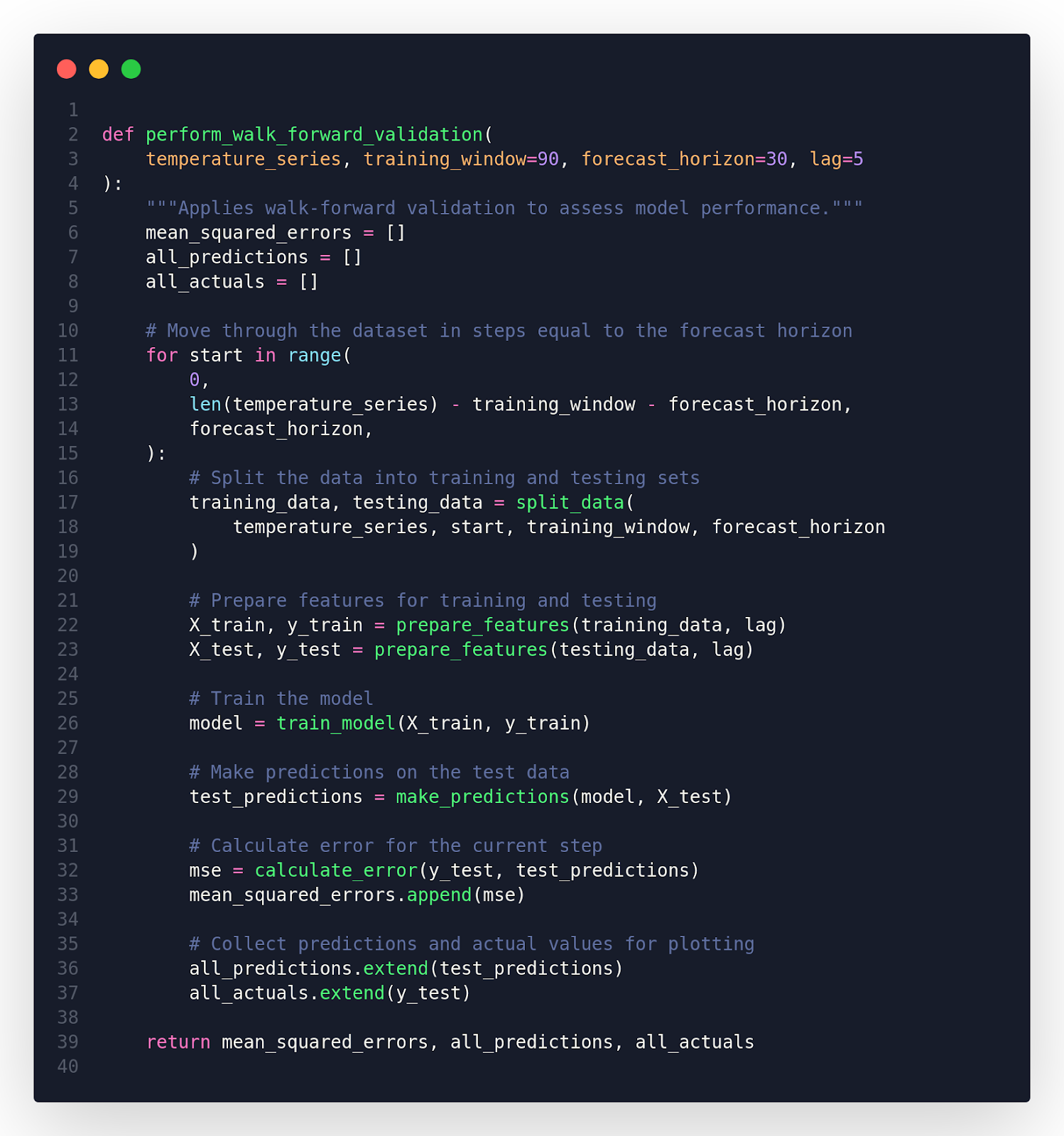
Function to Perform Walk-Forward Validation
Execute Walk-forward Validation & Show Resulting Plot
After executing the following code we can get the following output.
Output
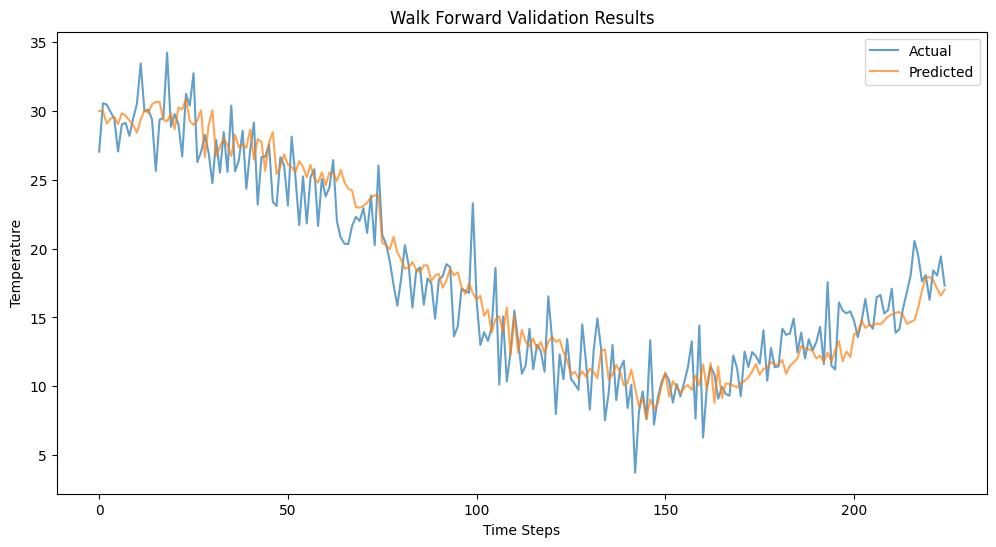
Key Benefits of This Approach
- Realistic Testing: We’re always predicting future values using only past data
- Multiple Evaluations: We get error metrics across different periods
- Capture Seasonality: By using appropriate window sizes, we can capture seasonal patterns
- Early Warning: We can detect if model performance degrades over time
Best Practices for Walk Forward Validation
- Window Size Selection:
- Training window should capture seasonal patterns
- The test window should match business requirements
- Step Size:
- Smaller steps = more evaluations but higher computation
- Larger steps = faster but might miss patterns
- Performance Metrics:
- Track performance across different time periods
- Monitor for degradation in recent windows
- Data Preprocessing:
- Apply transformations within each window
- Avoid looking ahead in the validation process
- Consider your data characteristics:
- Seasonality
- Trends
- Pattern changes over time
- Monitor performance across different periods:
- Look for patterns in errors
- Check if certain seasons are harder to predict
End Note
Walk Forward Validation is a powerful tool for evaluating time series models. It helps ensure that our models perform well in real-world conditions where we can only access historical data. While it might be more complex than simple train-test splits, the benefits of more realistic and robust model evaluation make it worth the effort.
The goal isn’t just to have good metrics, but to have a model that performs reliably in production. Walk Forward Validation helps us achieve this by simulating real-world conditions during the development phase.
Happy forecasting! 📈
Leave a Reply
Want to join the discussion?Feel free to contribute!