Making Large Language Models Faster and More Energy Efficient with BitNet and bitnet.cpp
Large Language Models (LLMs) are becoming increasingly strong, but they also demand more computing power and energy. Researchers have created BitNet and its supporting framework, bitnet.cpp, to tackle these obstacles, providing a more intelligent approach to executing these models. In this article, we will explain the purpose of this innovative technology and how it can be advantageous for all individuals, particularly those utilizing AI on their personal devices.
What is BitNet?
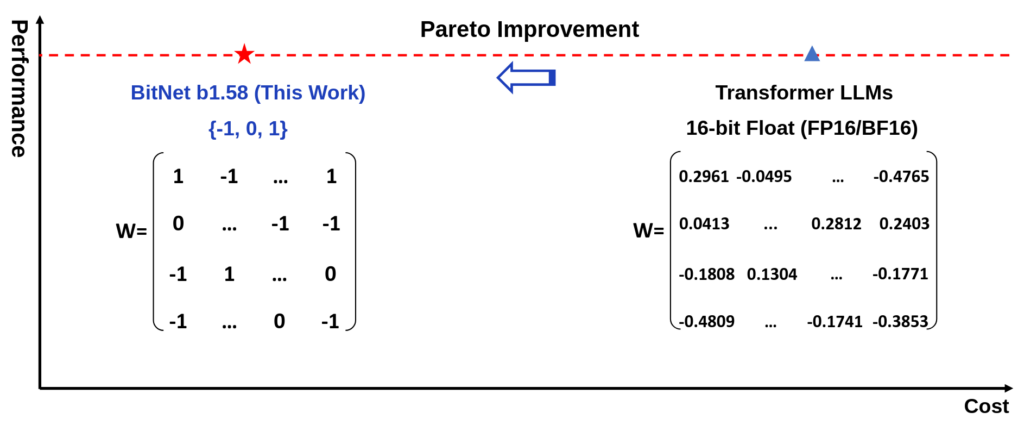
BitNet is a form of LLM that operates with data at either 1-bit or 1.58-bit accuracy. This means it saves and processes compressed data formats rather than high-precision numbers. Consider it as shorthand writing, conveying the same message with fewer symbols. Lower precision enables faster model performance and reduced energy consumption without compromising output quality.
What is bitnet.cpp?
bitnet.cpp is the program structure created to effectively operate these 1-bit LLMs on common devices, such as laptops and desktops. The structure enables big models to run on standard CPUs instead of needing costly GPUs. This simplifies the use of AI on local devices, including those not designed for machine learning.
Why Should You Care About 1-Bit AI?
Efficiently operating LLMs offers a number of advantages such as-
- Quicker AI replies – Say goodbye to waiting for lengthy calculations.
- Energy conservation – Beneficial for mobile devices like laptops and phones, especially important for extending battery longevity.
- On-device AI – No need for cloud dependence to operate complex models, improving privacy and accessibility.
How Fast and Energy Efficient is bitnet.cpp?
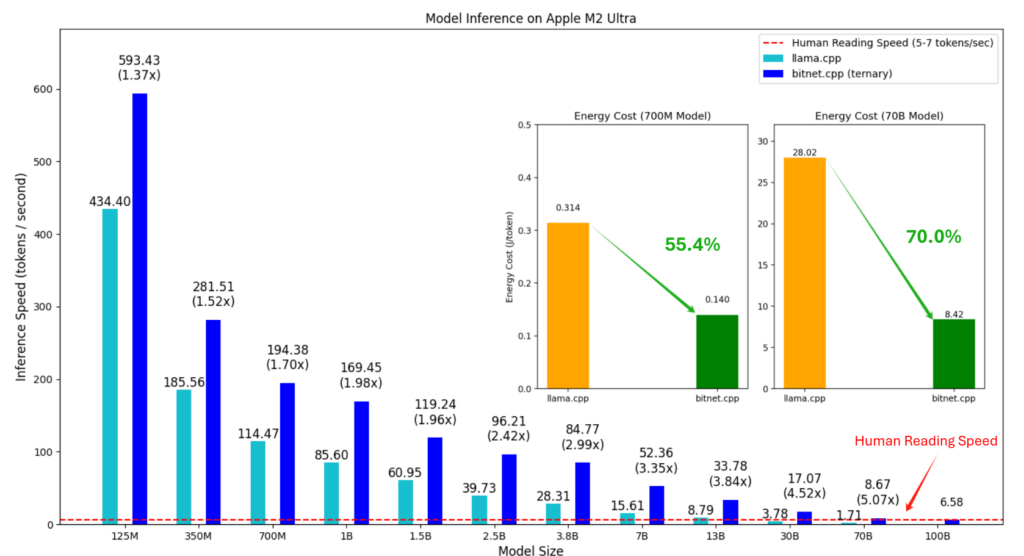
The developers conducted experiments on bitnet.cpp using two different CPU models.
- Apple’s M2 Ultra processor, found in devices such as the Mac Studio.
- Intel i7-13700H can be found in certain laptops.
The findings indicate that bitnet.cpp outperforms older frameworks by a factor of 2 to 6 in terms of speed. It can also reduce energy usage by 55% to 82%, depending on the size of the model and the type of CPU. As an illustration, a model powered by the Intel processor used 70% less energy than the standard configuration.
Optimized Kernels (The Secret Sauce)
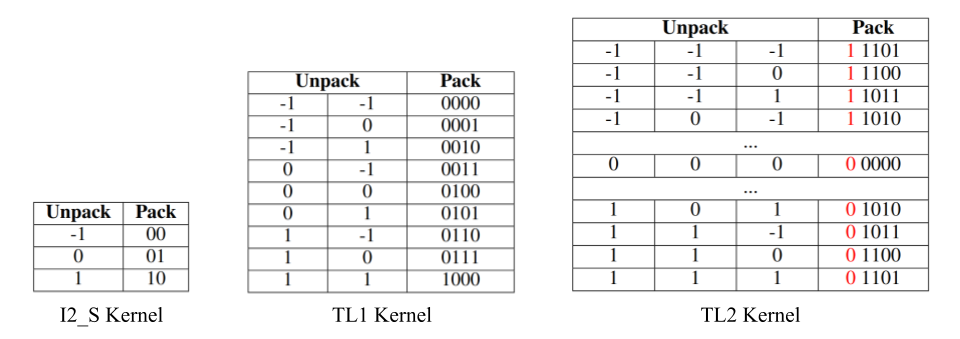
The efficiency of bitnet.cpp is largely attributed to its kernels, which are small software components aiding the CPU in swift data processing. Here’s a basic overview of the functions of these kernels.
- I2_S Kernel: Changes accurate numbers into 2-bit values in order to conserve memory space.
- TL1 Kernel compresses two numbers into a 4-bit format, reducing both storage requirements and processing time.
- TL2 Kernel: Compresses additional data effectively for tasks on devices with restricted memory.
These kernels ensure that the condensed data is unpacked and processed accurately to maintain the precision of the model’s predictions.
Can bitnet.cpp Run Big Models?
Yes! It has the capacity to manage models with up to 100 billion parameters, which are massive models capable of complex tasks. The system can reach speeds similar to those of human reading (5 to 7 words per second) when operating big models on a typical CPU.
What’s Next for 1-Bit AI?
The developers of bitnet.cpp are currently in the process of broadening compatibility to additional devices such as smartphones and specialized chips such as GPUs and NPUs. They also aim to investigate the efficient training of 1-bit models, which will further cut down on the requirement for high-end hardware.
BitNet and its corresponding code, bitnet.cpp, provide a peek into a potentially more effective AI future where robust language models can operate efficiently on common devices without excessive energy consumption. Whether you value local AI for privacy concerns or desire extended device battery life, this new platform makes AI more accessible to all.
This is just the start – keep watching for more improvements in making AI more intelligent and compact!
Reference
- Ma, S., Wang, H., Ma, L., Wang, L., Wang, W., Huang, S., … & Wei, F. (2024). The era of 1-bit llms: All large language models are in 1.58 bits. arXiv preprint arXiv:2402.17764.
- Wang, J., Zhou, H., Song, T., Mao, S., Ma, S., Wang, H., Xia, Y., & Wei, F. (2024). 1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs. ArXiv. https://arxiv.org/abs/2410.16144
- https://github.com/microsoft/BitNet
Leave a Reply
Want to join the discussion?Feel free to contribute!