Efficiently Fine-tuning Large Language Models with QLoRA: An Introductory Guide
Fine-tuning large language models (LLMs) such as LLaMA and T5 can produce impressive results, but the memory and hardware required for traditional 16-bit fine-tuning can be a major obstacle. A new method called QLoRA (Quantized Low-Rank Adapter) changes that, enabling efficient fine-tuning on large models using much less memory. This article simplifies the core concepts behind QLoRA, how it utilizes quantization, and how it allows for high-performance model customization on a single GPU.
What is QLoRA?
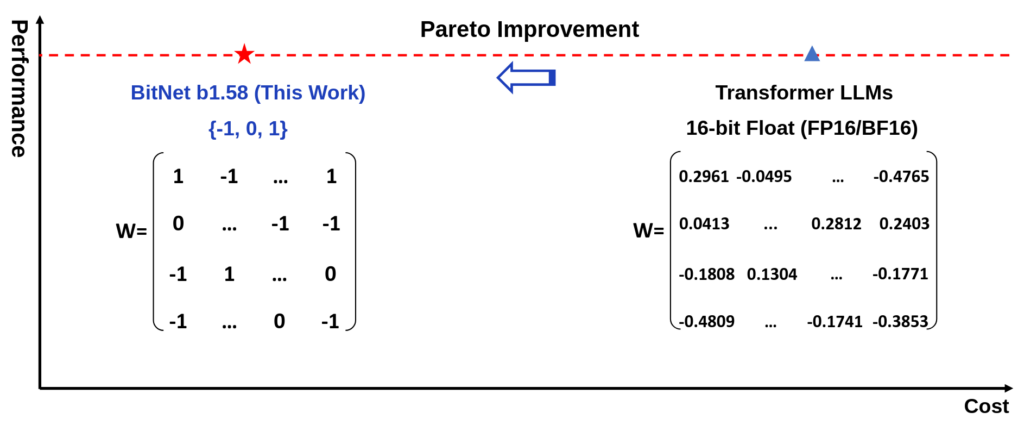
QLoRA is a method that allows fine-tuning of quantized models using Low-Rank Adapters (LoRA), making it possible to achieve high performance with a fraction of the typical memory usage. By freezing the original 4-bit quantized model and backpropagating gradients only through lightweight LoRA adapters, QLoRA reduces the memory needed to fine-tune a large model, like one with 65 billion parameters, from over 780GB to under 48GB. This makes it possible to fine-tune large models on a single GPU.
How Does QLoRA Work?
QLoRA introduces three major innovations that enable efficient tuning of quantized models without sacrificing performance.
Read more