It’s an open secret that we are entering into the magical world of large language models (LLMs). We have already celebrated the first anniversary of ChatGPT a few weeks back. In the meantime, we have been introduced to a wide range of large language models performing several tasks including text generation, code generation, image manipulation, and even video analysis. We can utilize these large language models through prompting. But there are some major concerns to be addressed.
How much access do we have and at what cost?
Utilizing a large language model through prompting requires either access to commercial APIs or significant computation power. Both of the approaches are expensive. Privacy has also been a major concern while utilizing commercial LLMs.
If these LLMs have such high requirements, how can we customize them with low cost? How can we utilize LLMs for specific tasks?
Considering these issues, Viswanathan et al., have introduced a method for utilizing existing LLMs in an efficient way through natural language prompting. Their work was published by the Association for Computational Linguistics in the Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Their work aims to produce task-specific lightweight models that will outperform LLMs with a few hours of fine-tuning.
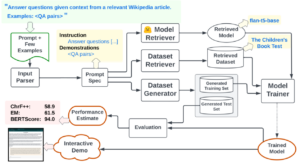
The Prompt2Model architecture seeks to automate the core machine learning development pipeline, allowing us to train a small yet accurate model from just a prompt.
We can have a glimpse of the whole process in Figure 1. We can pick suitable models and datasets, generate synthetic data, and even fine-tune existing models on both retrieved datasets and synthetic datasets using natural language prompting. All we have to do is describe the task and give a few examples, the rest of the job will be done.
Great initiative indeed, but how does it work?
It’s pretty simple but works amazingly. This process goes through multiple steps including data retrieval, data generation, model retrieval, and supervised fine-tuning. The process starts with input preprocessing to identify the instruction and example. Based on the instructions and the example, it lists out the most suitable datasets and models for the task. Later the most suitable model is fine-tuned on selected datasets to produce a ready-to-use model.
How does it select the most suitable dataset and model?
The final decision for dataset selection is kept for the users. It shows the top k (default = 25) most suitable datasets. From these datasets, users can select the most relevant ones for a particular task. Users can also specify appropriate fields for the dataset.
For model selections, it ranks the relevant models. The ranking score is calculated based on the similarity between the user query and model description, and the logarithm of the total number of downloads. Before ranking the models, a primary filtration is conducted to filter out models whose size is higher than the threshold (3GB by default). After calculating the rank score, the top-ranked model is picked.
What if available datasets are not sufficient for fine-tuning the model?
It’s a very common obstacle faced in the field of Deep Learning, especially when we are talking about low-resource languages or a wide range of tasks. To address this issue, authors have added an extra feature to their work. They have added a dataset generator module, where they utilized automated prompt engineering to generate diverse datasets. Later the synthetic dataset can be added to retrieve the dataset for fine-tuning the model.
Everything seems decent. But how does it perform?
I believe we all are aware of the GPT family. Just to recall, this is the group of LLMs that is empowering ChatGPT. Prompt2Model has produced models that have outperformed get-3.5-turbo by an average of 20% while being 700 times smaller. The authors have evaluated the models in three downstream tasks; Question answering, Code generation from natural language, and temporal expression normalization. The performances have been compared with the performance of gpt-3.5-turbo as the baseline. Models produced by Prompt2Model have outperformed get-3.5-turbo in question answering and temporal expression normalization but did not perform well in code generation from natural language. Relatively low diversity in the generated dataset has been considered as the possible reason for this low performance. Another important finding is that the combination of retrieved dataset and generated dataset can achieve similar results to the custom annotated dataset while having more than 100 times low cost. This can be an important gateway to reduce the huge cost of data annotation.
Viswanathan et al. have introduced an impressive method for utilizing existing data and LLM resources with low cost and computation power. This approach can be proven beneficial and boost the usage of LLMs in more diverse and low-resourceful tasks. However, this approach has some scope for improvement. All of the experiments have been conducted using gpt-3.5-turbo API, which is closed-source and paid. The complexity of low-resource languages has not been addressed properly. The low performance in languages other than English can be observed in code generation tasks. Despite having these limitations, Prompt2Model has highlighted the possibility of using LLMs with low cost and computation power. We believe that the research questions initiated by Prompt2Model can lead us to more easy-to-access LLMs shortly.
Note: Technical details have been skipped to keep it simple. Please read the paper for more details.
Reference
- Viswanathan, C. Zhao, A. Bertsch, T. Wu, and G. Neubig, “Prompt2Model: Generating Deployable Models from Natural Language Instructions.” arXiv, Aug. 23, 2023. Accessed: Jan. 08, 2024. [Online]. Available: http://arxiv.org/abs/2308.12261